
































Technical terms in this article: content marketing, content marketing strategy, E-A-T, entity, knowledge graph, brand/brand, marketing, natural language processing (NLP), semantics, semantic search, SERPs, search intention, search engines, search engine optimization (SEO),
Authors, companies, and publishers as entities
Content is published by people such as authors and organizations such as companies, associations, authorities… These organizations and people are named entities (more on this in the Entities simply explained article). Since we have learned in the series of articles to date that Google is increasingly arranging or organizing content around entities (see e.g. the article Entity-based indexing, Google can use the respective entity to draw conclusions about the credibility and relevance of the document or content.
In the case of online content, at least two parties are usually involved. The author/producer who created the content and the publisher or domain where the content will be published. The author is not always directly an employee or owner of the domain. For example, in a guest article, the publisher and author are not identical.
When looking at SEO, entity classes such as organizations, products, and people play a special role, as they can be evaluated using the properties of a brand such as authority and trust or E-A-T. More on that later in this post.
Digital images of entities
Entities that can be assigned to certain entity classes such as people or organizations can have digital images such as the official website (domain), social media profiles, images, and Wikipedia entries. While images, especially in the case of people or sights, represent the visual image of the entity, the company website or the social media profile of a person is the image in terms of content.
These digital images are the central landmarks and are closely linked to the entity.
Google can primarily identify this link via external links on the website or the profiles with link texts that contain the exact entity name and/or the clear click behavior for search queries with the navigational, brand, or personal search intentions on the respective URL.
Read more: How Social Media Affects Your SEO
From entity to digital authority and brand
When looking at the characteristics of a brand, expertise, authority, and trust play a central role. In addition to the properties mentioned, popularity is also an important property of a brand, which, however, is not necessarily the focus of attention for authority or an expert. In summary, one can say that a brand also combines all the characteristics of authority plus a high level of awareness and popularity.
Google attaches great importance to brands and authorities when ranking websites.
As early as 2009, Google rolled out the Vince update, known as the brand update, which gave well-known offline brands significant ranking advantages. (More about the Vince update)
In this context, former Google CEO Eric Schmidt said:
The internet is almost becoming a ‘cesspool’ where false information thrives. Brands are the solution, not the problem. Brands are how you sort out the cesspool… Brand affinity is clearly hard-wired. “It is so fundamental to human existence that it’s not going away. It must have a genetic component.
Matt Cutts also commented on the subject:
Brands combine characteristics such as popularity, authority, and reputation, i.e. trust. I currently see trust and authority as one of the most important criteria, in addition to document relevance in relation to the search intention, as to whether Google allows content to appear on the first search results page or not. Google cannot afford to place content from untrustworthy sources in the user’s field of vision, especially with YMYL topics.
As a result, many affiliate projects that have not previously taken care of building a brand have come under the wheels. Popularity alone plays only a limited role. Amazon and eBay are very popular brands but lack authority in certain subject areas. This is why more specialized shops usually rank better than large e-commerce portals.
Google can recognize relationships between keywords, topics & entities
Google can use co-occurrences from entities and keywords to identify the topics with which entities are in context. The more frequently these co-occurrences occur, the greater the probability that there is a semantic connection. These co-occurrences can be determined via structured and unstructured information from website content, as well as via search terms.
If the entity “Empire State Building” is often mentioned together with the entity type “Skyscraper”, then there is a relationship. In this way, Google can already determine the relationship between entities and entity types, topics, keywords … when indexing content or processing a search query. Google can determine the degree of relationship via the average proximity in the texts and/or the frequency of co-occurrences.
As already mentioned, entities can be provided with labels or information for clear identification and for better classification in the ontological or thematic context. Exactly how Google does this in the search engine context is speculation. But I would like to explain below some ways how you can determine which properties Google associates an entity with.
Methods for determining trustworthiness (trust) and authority
In the following, I would like to explain some methods of how Google can determine the trustworthiness, credibility, and authority of a source or entity.
Sentiment analysis as a method for trust assessment
Sentiment analysis is used to assess the mood of a sentence or section of text. As can be deduced from Google’s NLP API, Google is able to carry out sentiment analysis. Sentiment analyses and entity analyzes are central sub-steps in natural language processing. In this way, Google can analyze the mood surrounding the naming of entities, including companies and people. If the entity is often mentioned in a negative context, it does not appear to be trustworthy, and vice versa. Reviews and ratings in particular could be an interesting source for such analyses.
Here is an excerpt from the Google NLP API documentation:




“Per-entity sentiment analysis combines entity analysis with sentiment analysis and attempts to discern the attitude (positive or negative) expressed in the entities of the text. Each entity sentiment is represented by numerical score and magnitude values and determined for each mention of an entity. These scores are then aggregated into an overall sentiment score (score and magnitude) for an entity…
The Natural Language API processes the given text to extract the entities and determine the sentiment. A request for sentiment analysis per entity returns a response containing the following information: the entities found in the document content, the mentions entry for each mention of the entity, and the numeric values of score and magnitude for each mention, as described in Interpreting sentiment analysis values . The score and magnitude values for an entity are a summary of the specific score and magnitude values for each mention of the entity. The score and magnitude values for an entity can be 0 if sentiment in the text scores low, resulting in a magnitude of 0, or if sentiment is mixed, resulting in a score of 0.”
Also the following patent.
Sentiment detection as a ranking signal for reviewable entities
The latest version of this Google patent was signed in October 2017. The patent describes in part the process of sentiment analysis via Google’s NLP API.
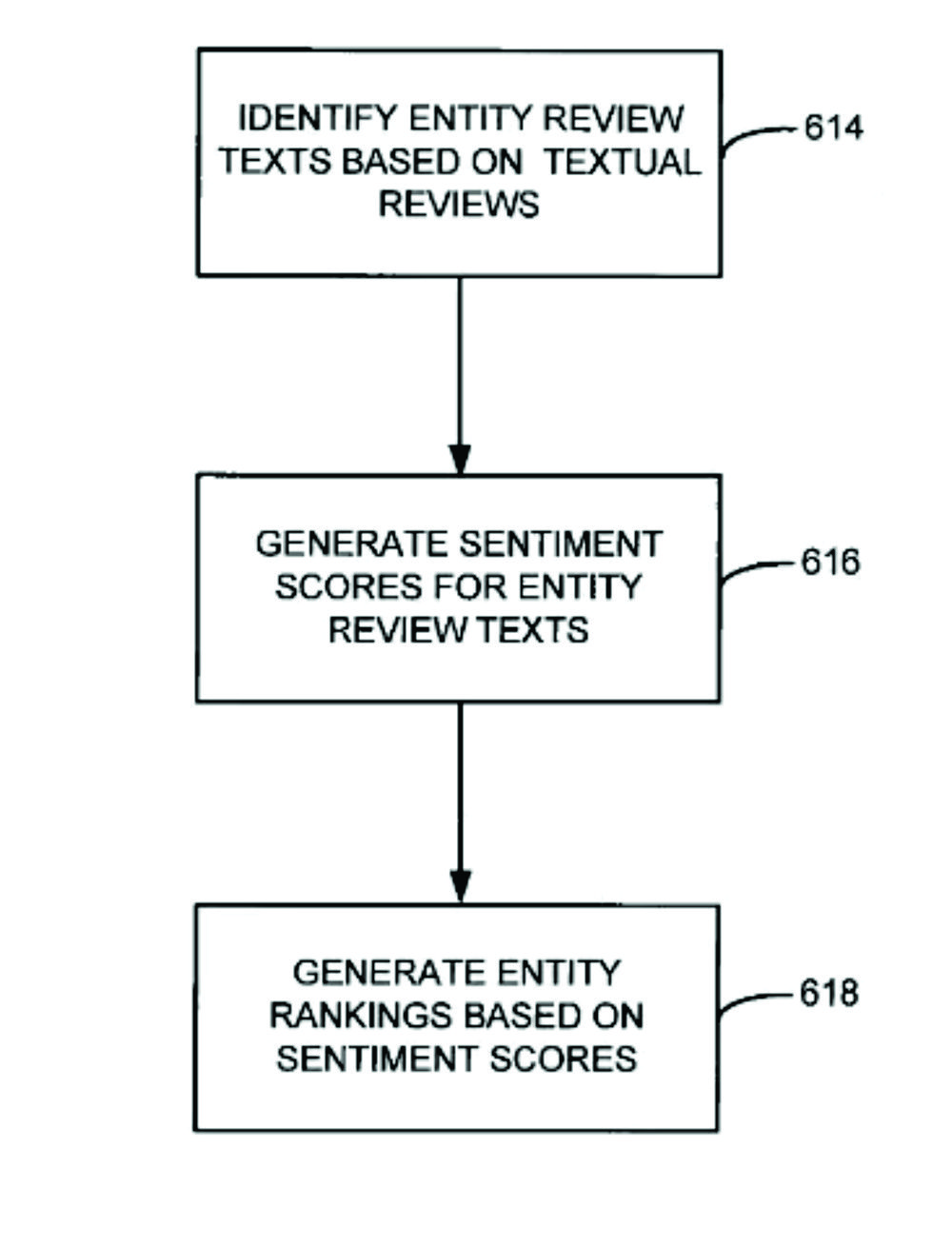
The patent describes how moods around assessable entities in documents can be identified on the basis of sentiment analyses. The results can then be used to rank entities and associated documents. Assessable entities include people, places, or things about which opinions can be expressed, such as B. restaurants, hotels, consumer goods such as electronics, films, books, and live performances.
The process for storage and ranking is performed via a ranking analysis engine and an entity ranking data repository. The Entity Ranking Data Repository consists of a database for the sentiments, the entity ratings, and the user interaction. In the database for user interaction, user behavior is recorded in the SERPs with entity-relevant documents. The process includes typical NLP sub-steps such as Part of Speech Tagging.
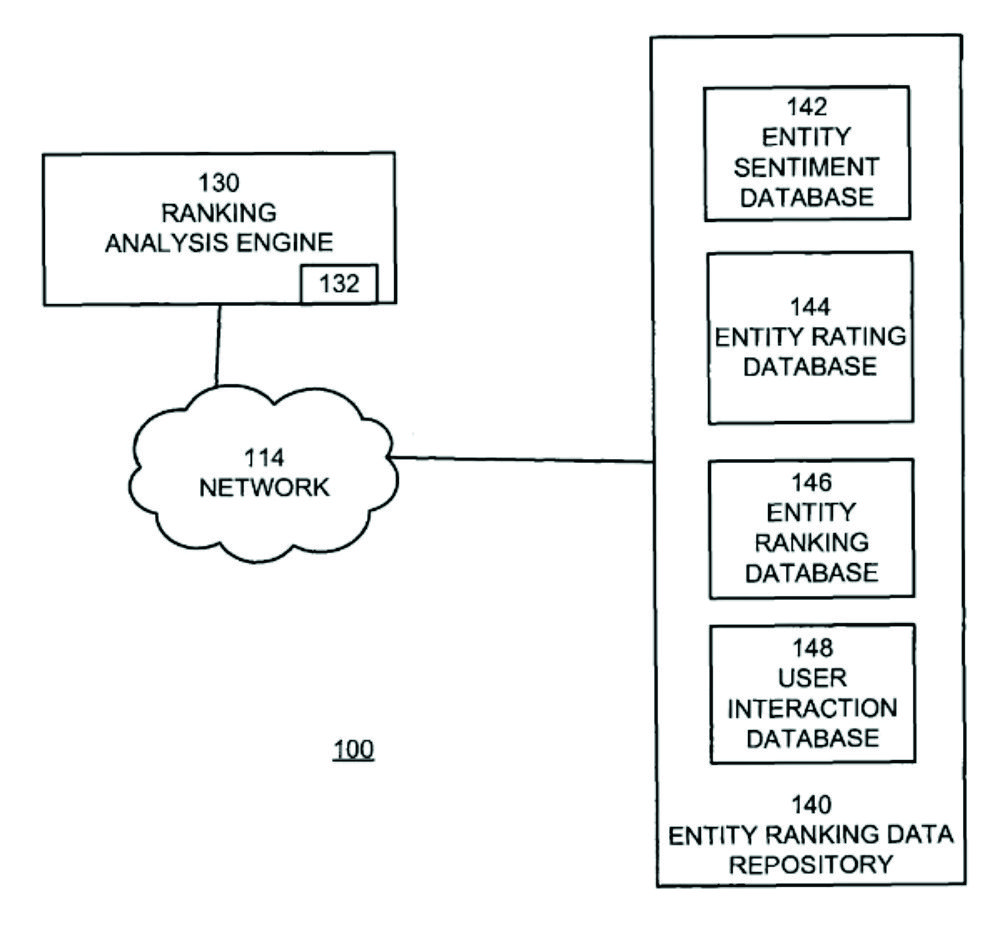
The entities stored in the sentiment database are represented by tuples of entity ID, entity type, and one or more reviews. The reviews are provided with different scorings, which are calculated in the Ranking Analysis Engine.
In the Ranking Analysis Engine, sentiment scores are determined for the respective ratings, including additional information such as the author.
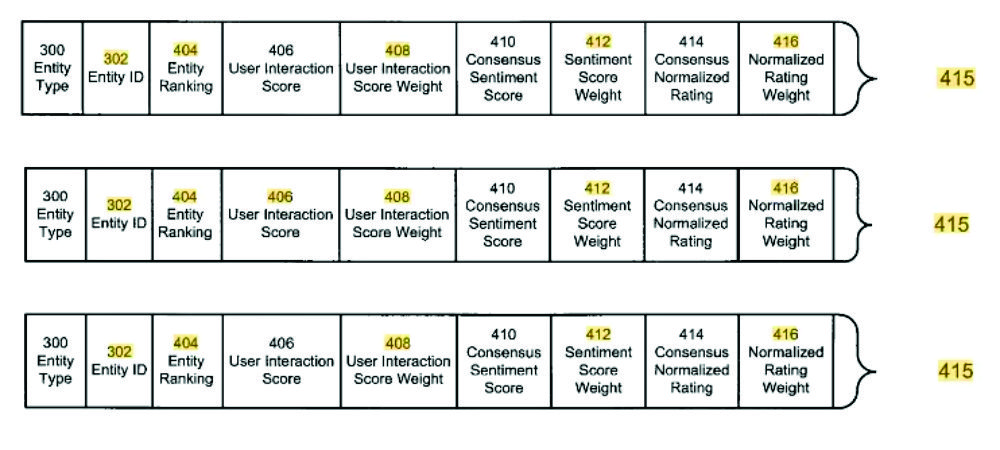
- User Interaction Score
- consensus sentiment score
To determine a user interaction score, user signals such as SERP-CTR and length of stay are discussed.
The User Interaction Score 406 is generated using user interaction metrics such as user click-through and time spent at web pages associated with Ranked Entities 415 presented in search results. The Ranking Analysis Engine 130 monitors user interaction with results to generate user interaction metrics which are stored in the User Interaction Database 148.
In addition to the user interaction score, other scorings such as the Consensus Sentiment Score are included for the ranking.
410. Consensus Sentiment Scores 410 can be generated by averaging the Sentiment Scores 312 associated with a Reviewable Entity 315, selecting the median Sentiment Score 312 of the Sentiment Scores 312 associated with a Reviewable Entity 315 or selecting the Sentiment Score 312 which is most frequently associated with a Reviewable Entity 315.
It is also exciting to mention that the system learns domain-specific classifiers based on domain-relevant content or documents, which are used for domain-specific sentiment analysis. The domain describes the top hierarchy class such as Person. More on this in the article Everything You Should Know About Entity Types, Classes & Attributes.
In one embodiment, the domain-specific corpus 818 contains enough documents to constitute a representative sample of how sentiment is expressed in the domain. Likewise, the domain-independent corpus 820 contains enough documents to constitute a representative sample of how sentiment is expressed generally, exclusive of any specific domain.
Business category classification
The Google Patent Business Category Classification from 2015 describes how documents and entities can be assigned to an industry or business category. In the first step, documents are assigned to an entity. By naming possible business areas or categories, the entity can be assigned to them. Furthermore, a relevance assessment in relation to an industry can be carried out for an entity. This can be due to
- the frequency of entity mentions in connection with the category per document
- the set of documents that these co-occurrences contain
- in relation to the general mentions of the category
to be created. If this rating reaches a threshold, the entity is assigned to a category. The relevance scores are calculated for one or more business categories in relation to an entity and provide a measure of the relevance between a given business classification and the business unit.
In some aspects, the method further comprises steps for calculating a relevance score for each of the target of business categories, whereby the relevance score for each business category is based on the term frequency, the document frequency and the global frequency for each of the category phrases associated with that business category and associating one or more of the scraped of business categories with the business entity based on the relevance score calculated for each of the one or more of the scraped of business categories.
Examples of documents associated with the entity include web pages mentioning one or more business units, anchor text of hyperlinks to one or more company websites, web documents, advertisements and/or annual report feeds, etc.
The patent discusses possible areas of application for this method, e.g. for displaying entities on Google Maps.
Rating based on entity metrics
The Google Patent Ranking search results based on entity metric describes how an entity can be evaluated based on various metrics. The metrics are

- A score for the closeness of relatedness between entities and entity types. The score is determined via co-occurrences of entities with each other or with entity types.
- A score for mention ability or notability. Notability refers to how significant an entity is when related to a search query or other entity. To do this, the global popularity of the entity (i.e. the number of links, mentions in social media, etc.) is compared and divided by the popularity value of the entity type itself.
- A Contribution Share Score that describes an entity’s impact on a topic/industry. The post metric is based on external influence points like reviews, best-of lists, etc., and can be weighted to give certain types of post metrics (like reviews) more influence. For example, a critical review from a reputable expert would have a greater impact on the post metric than a review from Yelp users.
- A price metric measured based on awards…
In addition to these metrics, popularity, user selection, and reviews are also mentioned as ranking factors for entities.
- User selection and popularity are ranking factors for entities.
- Reviews count in ranking factors for entities.
Here is an excerpt from the patent:
Another illustrative metric is, for example, a notable entity type metric. In some implementations, the value of the notable entity type metric is a global popularity metric divided by a notable entity type rank. The notable entity type rank indicates the position of an entity type in a notable entity type list.
Another illustrative metric is, for example, a contribution metric. In some implementations, the contribution metric is based on critical reviews, fame rankings, and other information. In some implementations, rankings are weighted such that the highest values contribute most heavily to the metric .
Another illustrative metric is, for example, a prize metric. The prize metric is based on an entity’s awards and prizes. For example, a movie may have been awarded a variety of awards such as Oscars and Golden Globes, each with a particular value. In some implementations, the prize metric is weighted such that the highest values contribute most heavily to the metric.
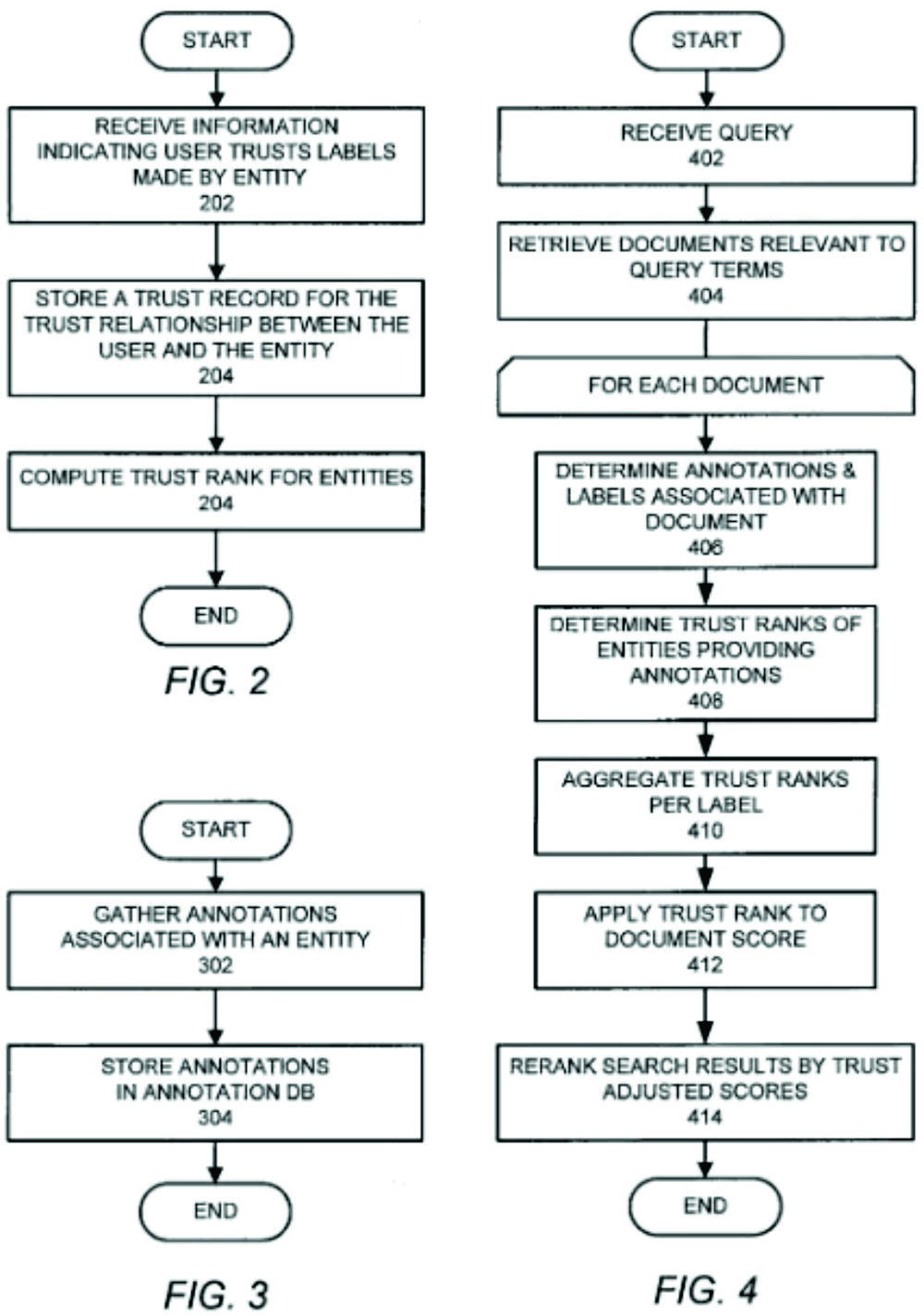
Search result ranking based on trust
The latest version of this very exciting patent was signed by Google in October 2017 and has the status “Application status active”. The patent describes how the ranking scoring of documents is supplemented based on a trust label.
The trust factors are used to adjust the information retrieval scores of the documents. The search results are then ranked based on the adjusted information retrieval scores.
The information about the labels is collected by a crawler and sent to the search engine system. This information can be from the document itself or from referencing external documents in the form of link texts or other information relating to the document or entity. These labels are linked to the URL and recorded in an annotation database.
In one embodiment of the present invention, a web crawler (not shown) obtains labels and trust information and sends it to search engine system 100 to facilitate subsequent usage in search result ranking.
Further signals can be given by the users themselves, e.g. via a trust button to a document and/or the publishing entity, or via a list in which the user can indicate for which topics he trusts the entity. This information is stored in a trusted database and based on this a trust factor is determined for each document. The names of the users and the rated labels are openly displayed in the SERPs along with the respective search result.
The Trust button is just one way of providing user feedback. But the patent says somewhat nebulously that all forms of signals can be used that provide information about the trust relationship between the entity and the user. For example, the frequency of visits to the website of the respective entity can also provide information about the level of trust.
The system can also examine web visitation patterns of the user and can infer from the web visitation patterns which entities the user trusts. For example, the system can infer that a particular user trust a particular entity when the user visits the entity’s web page with a certain frequency.
These trust signals can also be assigned indirectly via the website of a third entity, which in turn trusts the first entity.
The information from the Trust database is then used to rank the documents.
A document’s trust factor is a function of the trust ranks associated with the entities have labeled the document with labels that match the query labels. The search engine 180 adjusts each document’s underlying information retrieval score using the document’s trust factor, and then reranks the search results using the adjusted scores.
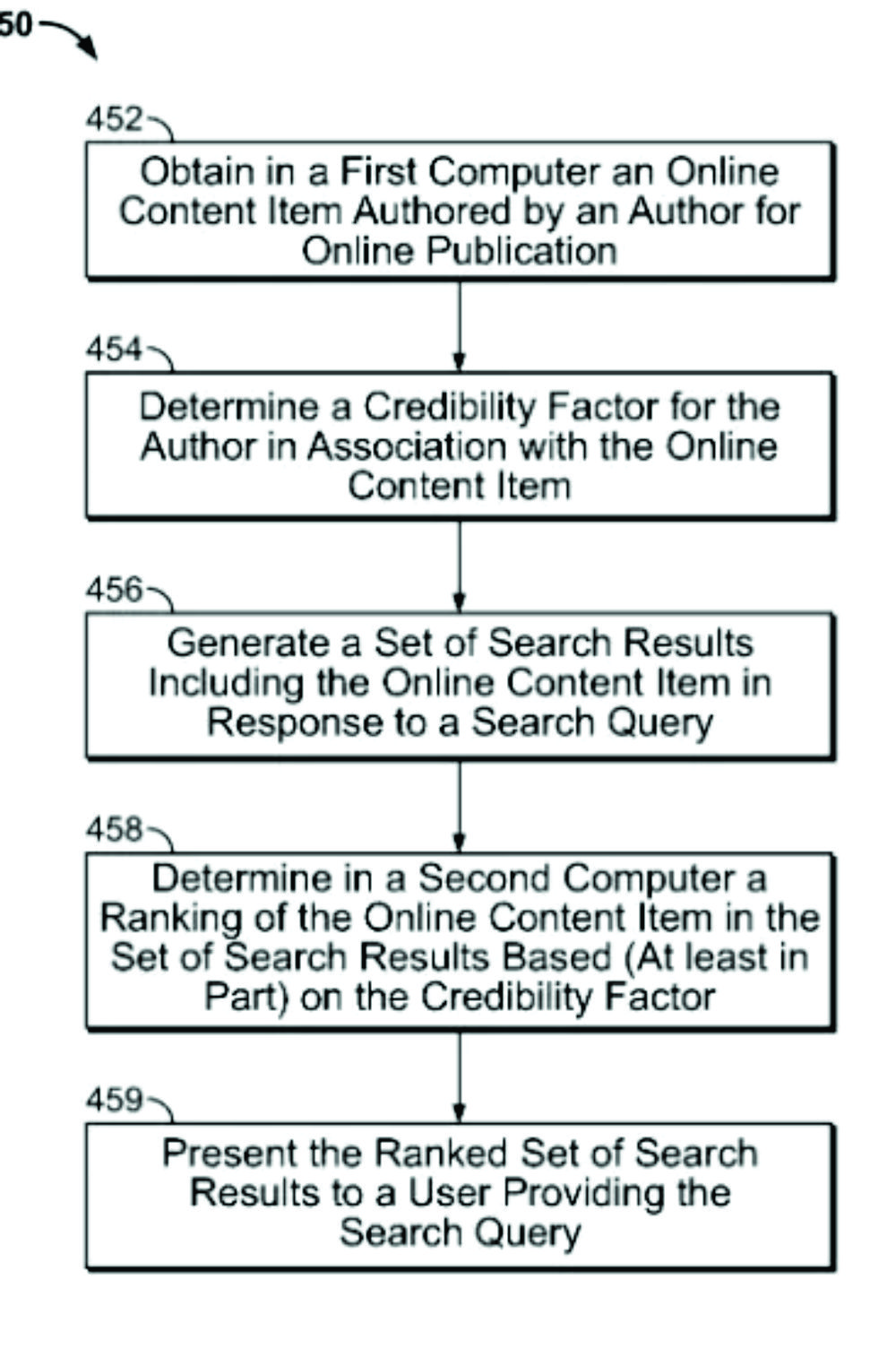
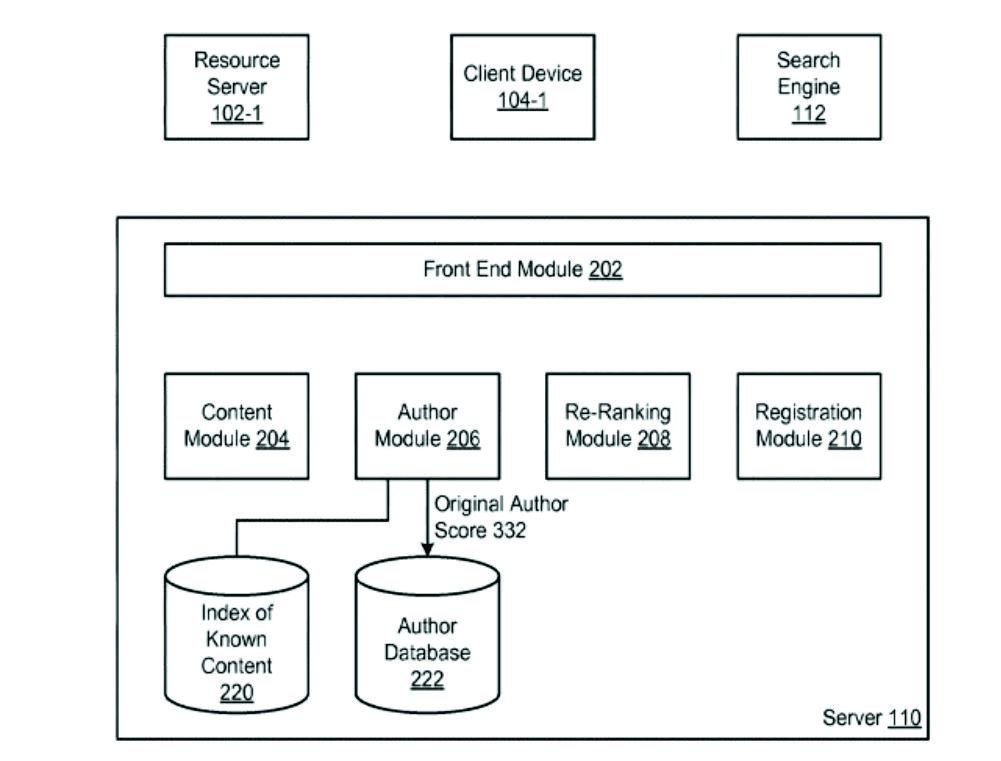
The credibility of an author of online content
This Google patent has the status “Application status is active”. It describes how a search engine can rank documents under the influence of an author’s credibility factor and reputation score. The following possible signals for a reputation score are mentioned:
- how long the author has been producing content in a subject area
- Awareness of the author
- Ratings of published content by users
- If the author’s content is published by another publisher with above-average ratings
- The number of content published by the author
- How long ago the author last published
- Ratings of previous publications on a similar topic by the author
Other interesting information about the reputation score from the patent:
- An author can have multiple reputation scores depending on how many different topics they publish content on.
- An author’s reputation score is independent of the publisher.
- The reputation score can be downgraded if duplicate content or excerpts are published more than once.
- The reputation score can be influenced by the number of links to the published content.
Furthermore, the patent addresses a credibility factor for authors. Verified information about the profession or the role of the author in a company is relevant for this. The credibility of the company also plays a role. The relevance of the profession to the topics of the published content is also decisive for the credibility of the author. The level of education and training of the author can also have a rash here.
The credibility factor can be further based on the relevance of the one or more fields to the author’s online content item. The verified information about the author can include feedback received about the author or the author’s online content item from one or more organizations. The credibility factor can be further based on the relevancy of the one or more organizations to the author’s online content item and the feedback received. The verified information about the author can include revenue information about the author’s online content item.
Systems and Methods for Re-Ranking ranked Search Results
This Google patent was signed in August 2018. It describes the refinement of search results after author scoring including citation scoring. Citation scoring is based on the number of references to an author’s documents. Another criterion for author scoring is the proportion of content that an author has contributed to a corpus of documents.
determining the author score for a respective entity includes: determining a citation score for the respective entity, wherein the citation score corresponds to a frequency at which content associated with the respective entity is cited; determining an original author score for the respective entity, whereby the original author score corresponds to a percentage of content associated with the respective entity that is a first instance of the content in an index of known content; and combining the citation score and the original author score using a predetermined function to produce the author score;
Knowledge-Based Trust: Estimating the Trustworthiness of Web Sources
This scientific paper from Google deals with how to determine the trustworthiness of online sources. In addition to the analysis of links, a new method is presented, which is based on checking the published information for correctness.
We propose a new approach that relies on endogenous signals, namely, the correctness of factual information provided by the source. A source that has few false facts is considered to be trustworthy.
Data mining methods are used for this, which I have already mentioned in the articles How can Google identify and interpret entities from unstructured content? and The Role of Natural Language Processing in Data Mining, Entities & Search Queries.
We call the trustworthiness score we computed Knowledge-Based Trust (KBT). On synthetic data, we show that our method can reliably compute the true trustworthiness levels of the sources.
The previous assessment of the credibility of sources based on links and browser data on website usage has weaknesses, as less popular sources have worse cards and unfairly come off badly, even though they provide very good information.
Using this approach, sources can be rated with a “trustworthiness score” without including the popularity factor. Sites that frequently provide incorrect information will be devalued. Sites that post information in line with the general consensus will be rewarded. This also reduces the likelihood that websites that attract attention with fake news will be visible on Google.
Producing a ranking for pages using distances in a web-link graph
This patent was signed by Google in the latest version in 2017 and the status is active. It describes how a ranking score for linked documents can be created based on the proximity to selected seed websites. The seed pages themselves are weighted individually.
In a variation on this embodiment, a seed page si in the set of seed pages is associated with a predetermined weight wherein 0<wi≦1. Furthermore, the seed page si is associated with an initial distance di where di=−log(wi).
The seed sites themselves are of high quality and the sources are highly credible.
On these pages one can read the following in the patent:
In one embodiment of the present invention, seeds 102 are specially selected high-quality pages which provide good web connectivity to other non-seed pages. More specifically, to ensure that other high-quality pages are easily reachable from seeds 102, seeds in seeds 102 need to be reliable, diverse to cover a wide range of fields of public interests, as well as well-connected with other pages (i.e. , having a large number of outgoing links). For example, Google Directory and The New York Times are both good seeds which possess such properties. It is typically assumed that these seeds are also “closer” to other high-quality pages on the web. In addition, seeds with large number of useful outgoing links facilitate identifying other useful and high-quality pages, thereby acting as “hubs” on the web.
According to the patent, these seed sites must be selected manually and the number should be limited to prevent tampering. The length of a link between a seed page and the document to be ranked can be determined using the following criteria, for example:
- position of the link
- the font of the link
- Degree of thematic deviation of the source page
- Number of outbound links from the source page
It is interesting that pages that have no direct or indirect link to at least one seed page are not even included in the scoring.
Note that however, not all the pages in the set of pages receive ranking scores through this process. For example, a page that cannot be reached by any of the seed pages will not be ranked.
Possible criteria for an algorithmic E-A-T evaluation
In summary, I would conclude from the findings that the following components have a significant influence on the algorithmic evaluation of sources such as authors and publishers according to E-A-T:
- how long the author / publisher has been producing content in a subject area
- Awareness of the author / publisher
- Reviews of the content published by the author/publisher by users
- The number of content published by the author/publisher on a topic
- How often the author/publisher publishes content on the topic
- Co-occurrences of the author / publisher in connection with terms from the topic environment
- Correctness of the published information in comparison with the “conventional opinion” or scientific knowledge (KBT)
- Frequent link proximity to seed sites of publisher/author content
- User signals such as CTR of publisher / author documents
- Mentions of the author / publisher in best-of lists
- Prizes and awards won by the author/publisher
- Mood/sentiment regarding the company/publisher/author
- These signals must be recognized by the crawler and evaluated algorithmically. As soon as an entity in the form of a company, publisher, author or product is rated via these signals, the documents associated with the entity can be rated according to E-A-T.
Author’s box and E-A-T
Since the author’s box is being discussed a lot at the moment, I would like to go into it briefly at this point. An author box by itself will not have much impact on ranking. It can help to relate content to an entity. However, if the author is not yet recognized as an entity by Google or does not have thematic credibility or authority that can be recognized algorithmically by Google, an author box will have no influence on the ranking.
Unvalidated entities next to Knowledge Graph
I think Google has more entities on screen than just the ones officially recorded in the Knowledge Graph. Since entities can be analyzed via the Knowledge Vault or Natural Language Processing both in search queries and in content of any kind, there will be a second invalid database in addition to the Knowledge Graph. All entities could be recorded in this database that were recognized as an entity, that are assigned to a domain and an entity type, but are not socially relevant enough for the display of a knowledge panel.
For performance reasons, something like this would make sense, since such a repository would not allow starting from scratch again and again. I think all entities are stored there for which the information regarding correctness cannot (yet) be validated.
This would allow Google to apply the signals explained to other entities in addition to those recorded in the Knowledge Graph in order to carry out E-A-T assessments.
Conclusion for SEOs and content marketers
As already explained in my article Branding & the new Google Ranking: Why SEO is no longer enough… in 2014, the brand and authority are playing an increasingly important role in search engine optimization. This ensures that the search results can no longer be influenced by SEO techniques alone. It’s also about marketing and PR. In addition to the well-known SEO on-page basics to ensure crawlability, indexing control, optimization of internal links (see here) and website hygiene, the triad of relevance, trust and authority must be observed first and foremost.
For findability on Google, but also in general, SEOs and online marketers should focus on the effects on the ranking through brand building in addition to content, link building and crawling and indexing control. This requires collaboration with the people responsible for branding and PR. In this way, possible synergies can already be taken into account during the conception of the campaign.
In summary, it can be said that it makes sense to associate your own brand with topics/products for which you want to be found in all marketing and PR activities with a view to the Google ranking. Be it in marketing campaigns, marketing cooperations such as Home2go or Footlocker have done to promote certain search query patterns.
One should try to generate co-occurrences and links from topic-related editorial environments via PR campaigns or content marketing campaigns.
In general, one can say that own content via owned media and signals via co-occurrences or brand and domain names in certain subject areas can increase the authority of a brand and thus the ranking for keywords that are located in these areas.
The more clearly Google can identify the positioning of the company, author, publisher…, the easier it will be to rank thematically relevant content linked to this entity.

